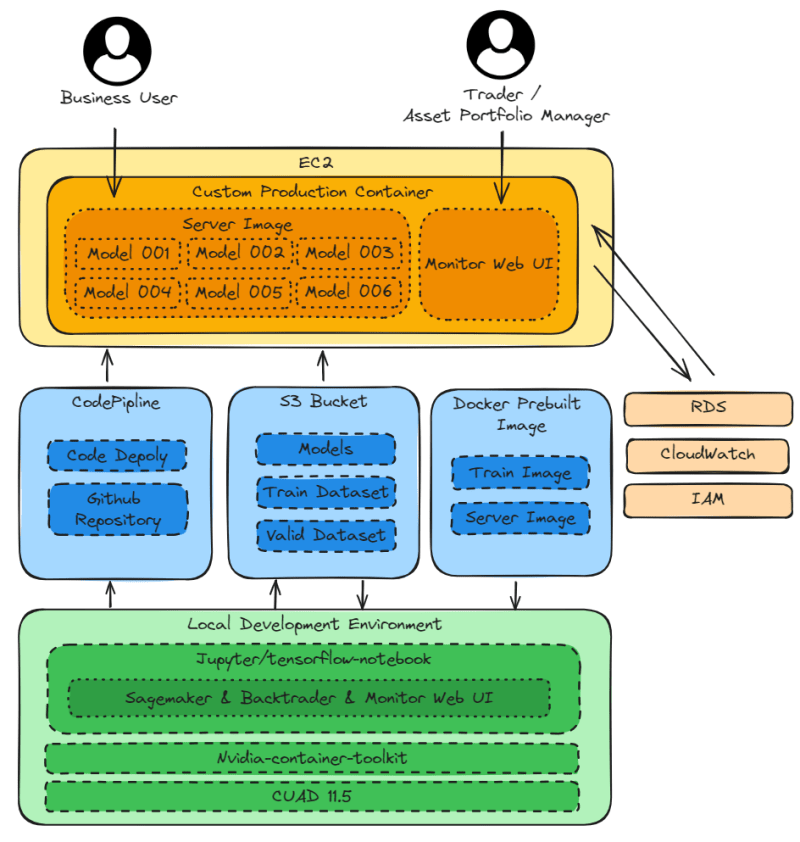
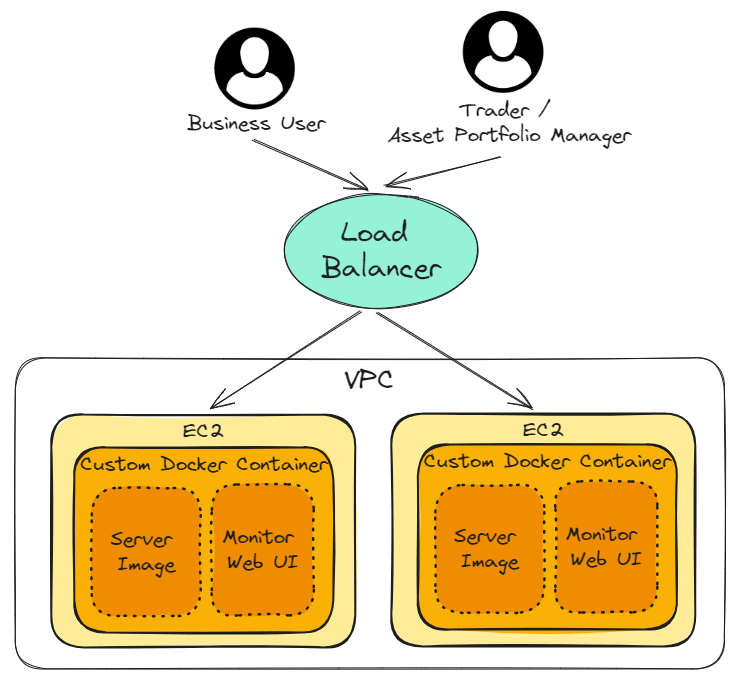
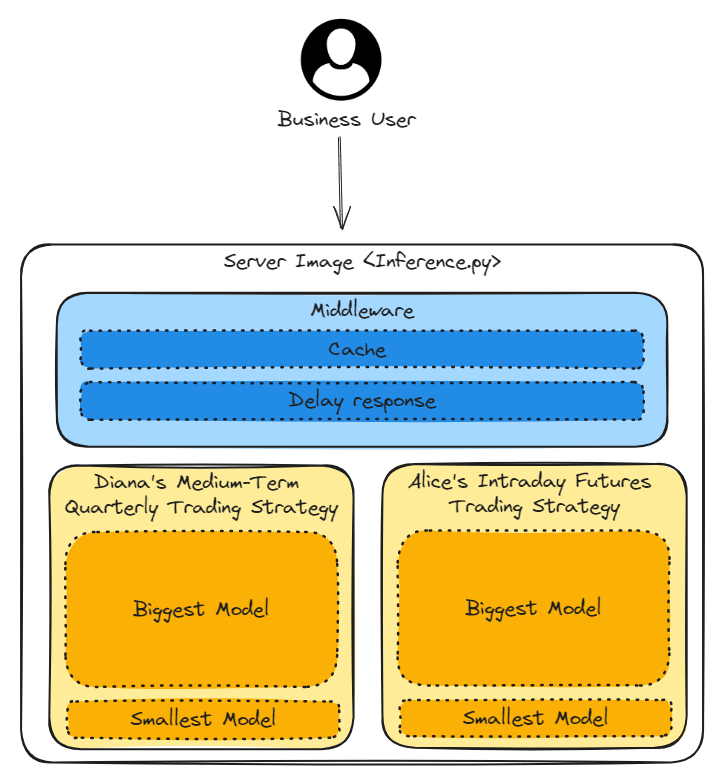
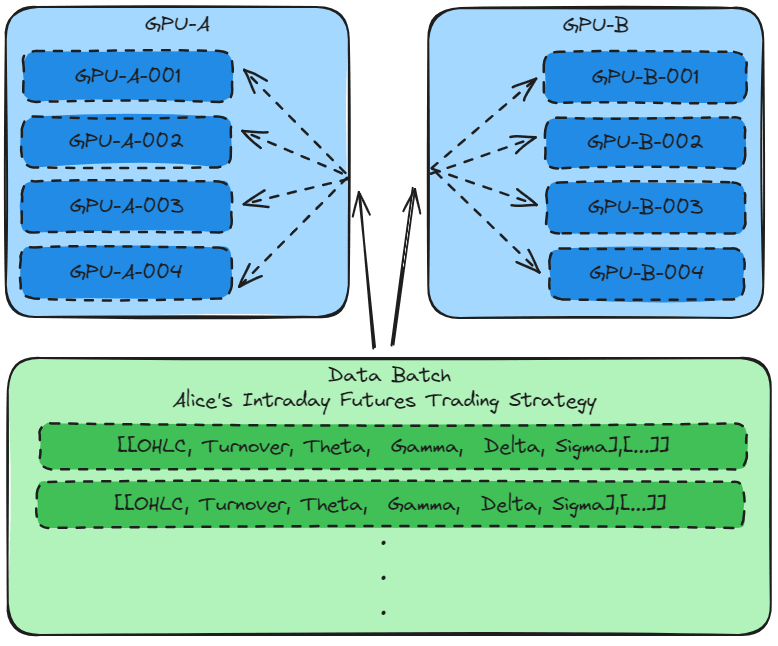
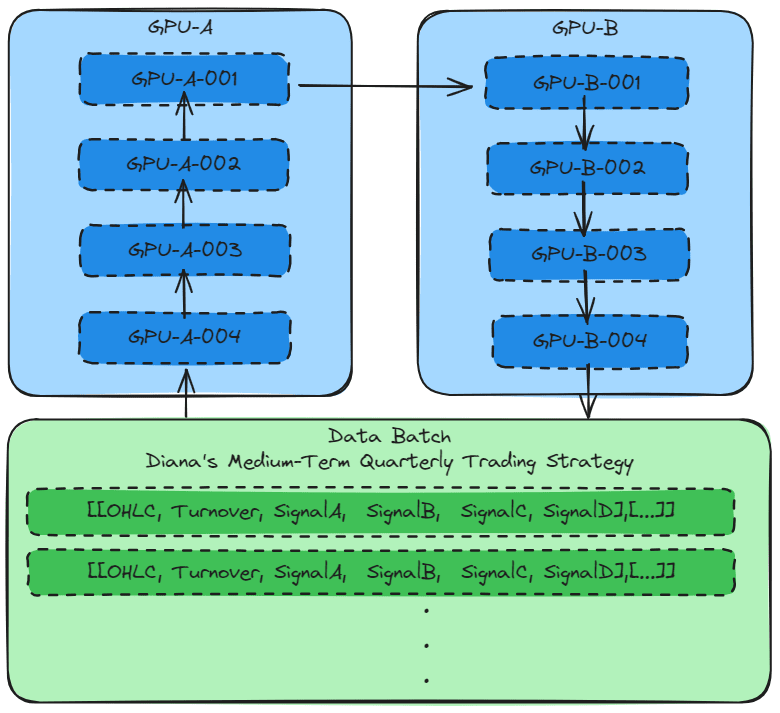
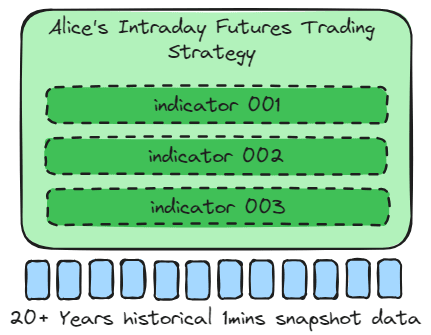
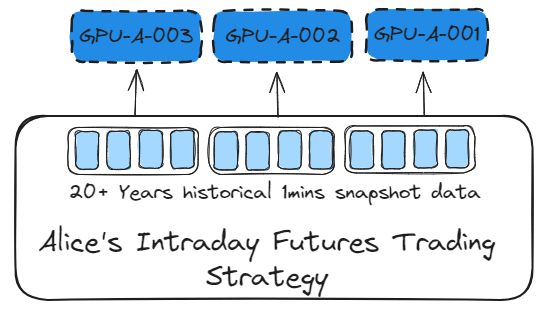
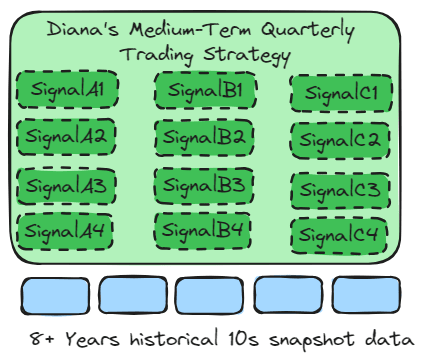
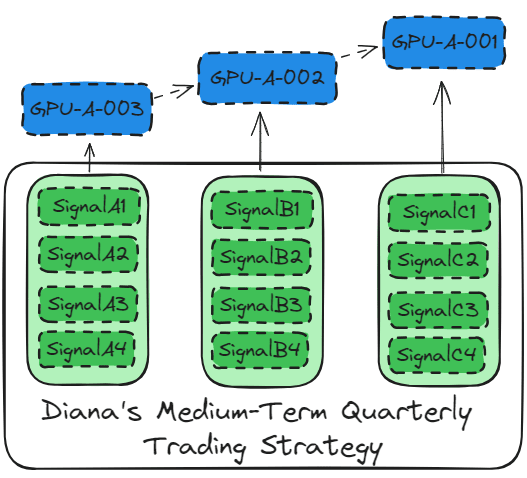
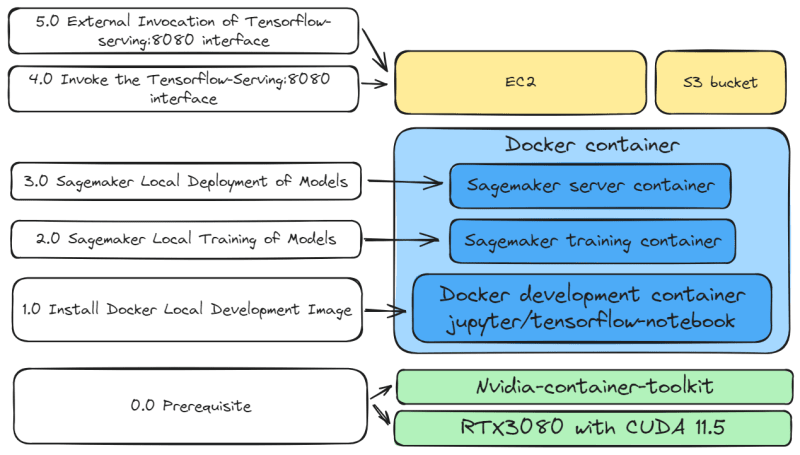
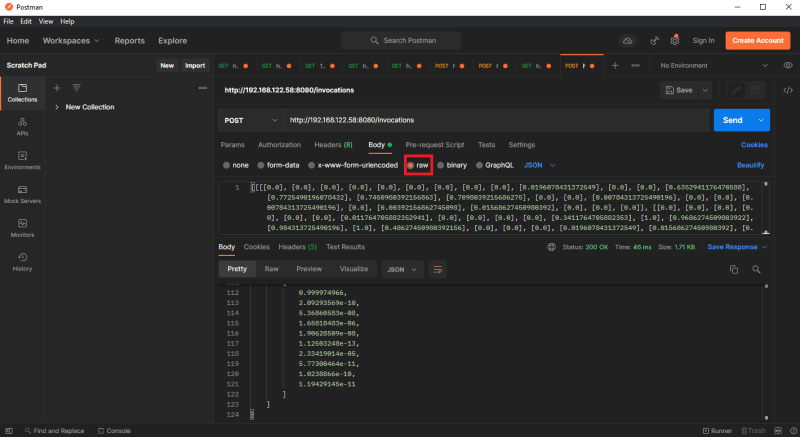
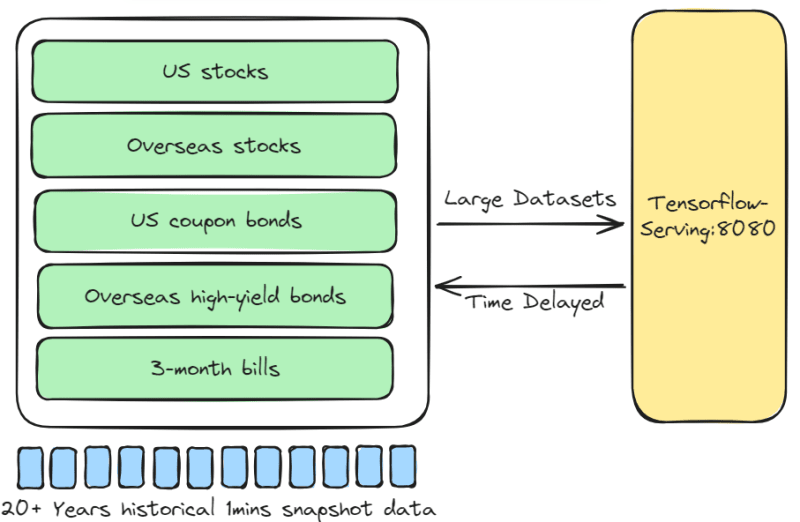
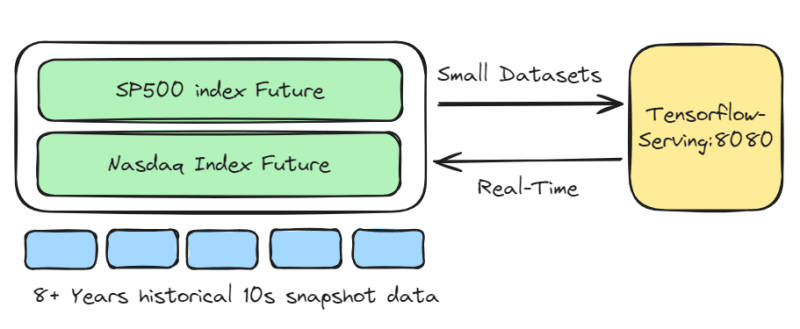
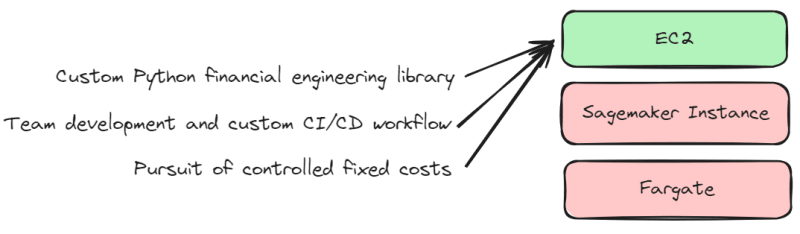
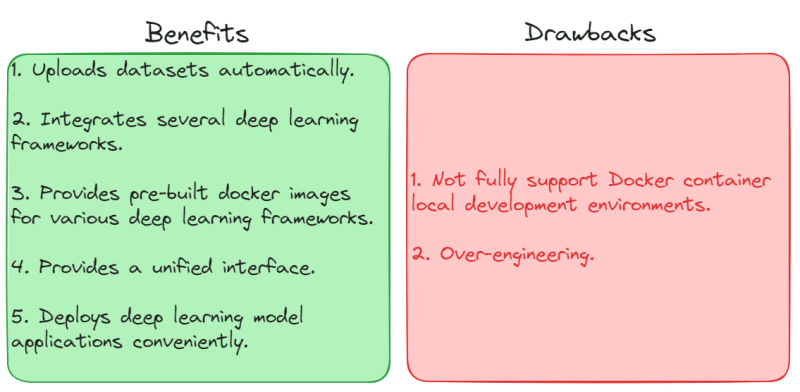
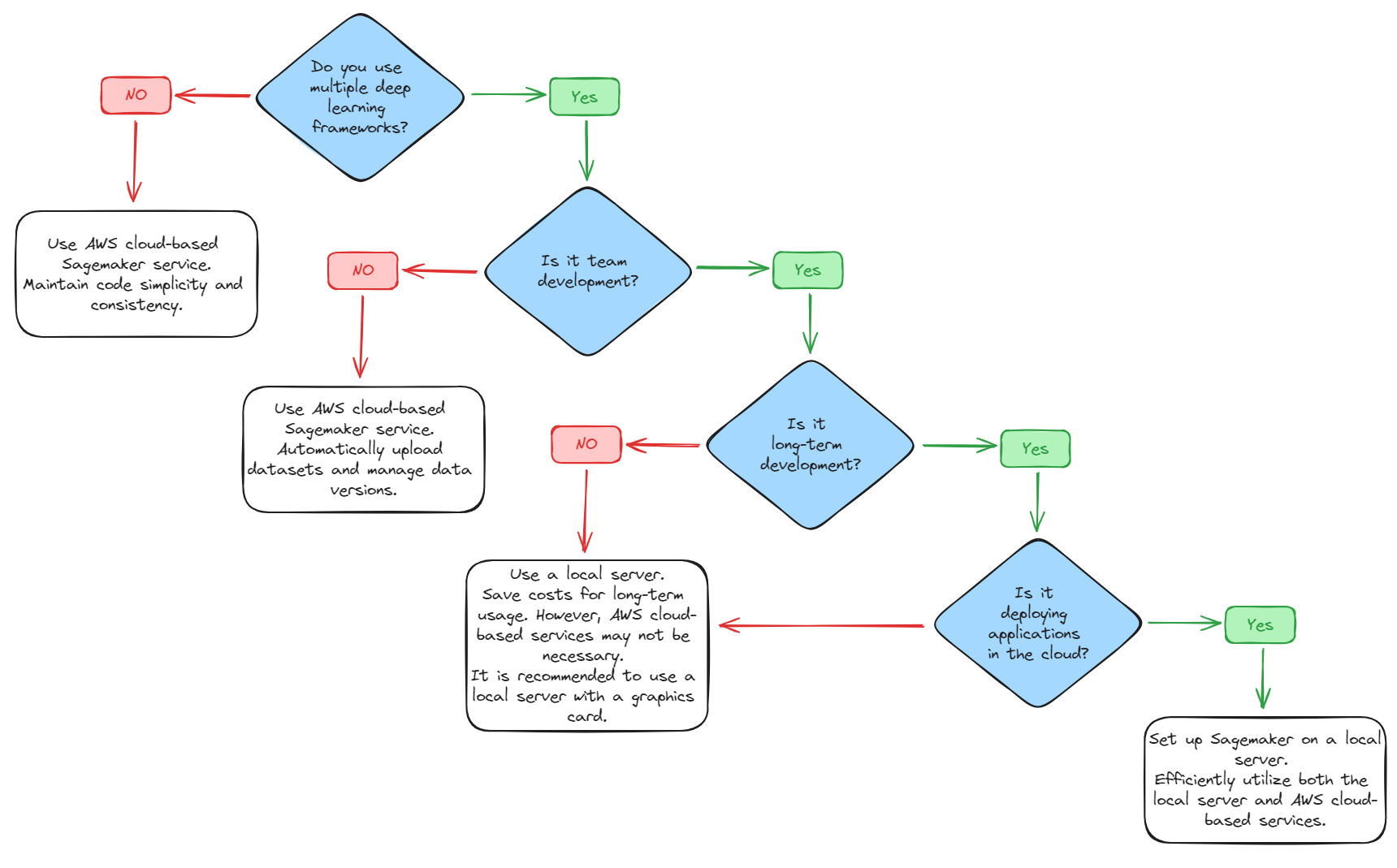
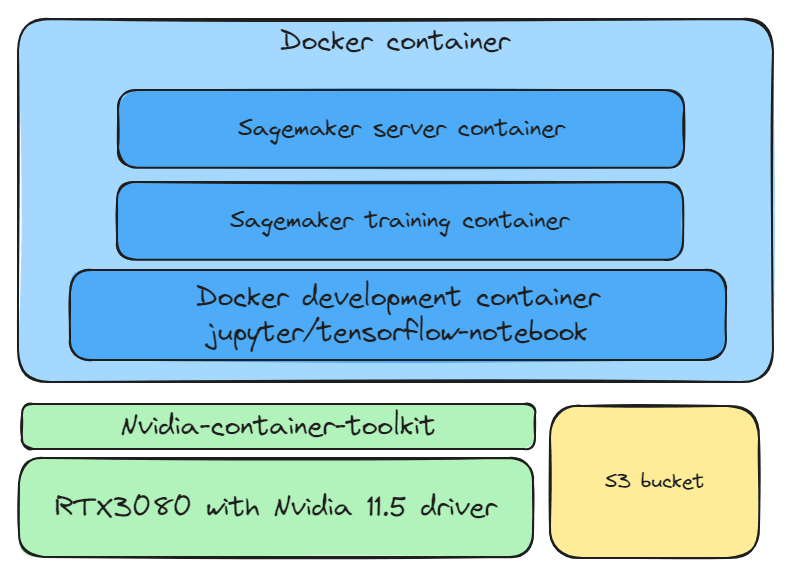
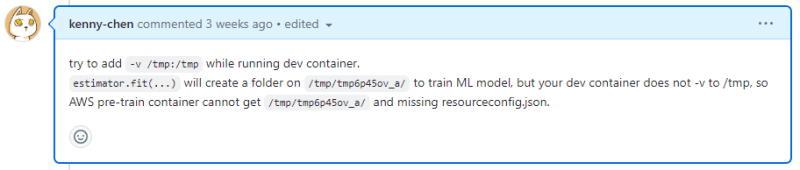
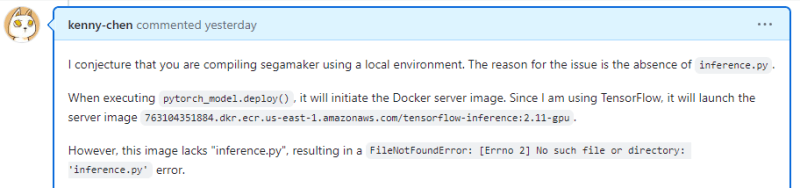
The previous chapter AWS DevOps+Q Agile Delivery of 16 Leadership Principles for the Financial Services Industry shared how AWS DevOps pipelines can solve pain points in the financial services industry, and utilize the Amazon 16 Leadership Principles.
In this chapter, you will learn how to build an AWS DevOps pipeline:

| AWS Services | Description |
|---|---|
| IAM | Identity and Access Management |
| EC2 | Cloud-computing platform |
| Elastic IP address | Static IPv4 address designed for dynamic cloud computing |
| Route53 | Cloud domain name system (DNS) service |
| CodeDeploy | Automate application deployments to Amazon EC2 instances |
| GitHub Actions | Easy to automate all your software workflows |
| Pricing Calculator | Create an estimate for the cost of your use |
2.0 AWS DevOps Pipeline
2.1 Pre-requisites
2.1.1 Knowledge Pre-requirements
- Create an
EC2server - Have a GitHub account and know basic
Github Actions. - Know how to setup
NGINX - Know basic AWS services, including
EC2,CodeDepoly,IAM.
2.1.2 Project Requirements
First upload a simple static web project codedeploy.nginx.001 on Github, which includes:
| Object | Location | |
|---|---|---|
| index.html | ./ | Static Web Page |
| ic_alana_002_20241022_a.jpg | ./icons | images on a static web page |
| appspec.yml | ./ | CodeDeploy code |
| application-stop.sh before-install.sh after-install.sh application-start.sh validate-service.sh |
./scripts | CodeDeploy code |
| appspec.yml | ./github/workflows | CodeDeploy code |
Also, GitHub access tokens are needed to configure codeDeploy permissions.

Github -> Setting -> Developer Setting -> Tokens. Add a GitHub access token.
2.2 Creating IAM Roles
A good naming style is important because as the number of IAM roles grows, it can be confusing for developers.
1 | AmazonSageMaker-ExecutionRole-20240805T101031 |
{service}-{role}-{datetime}-{version}. AWS Bedrock and SageMaker auto-generated IAM naming style.
1 | AWSCodeDeployService-EC2AccessCodeDeployRole-20241024T000000 |
This is the clear IAM naming style, so we will create three IAM roles for EC2, CodeDeploy, and GitHub Actions, respectively, following this official IAM naming style.
2.2.1 AWSCodeDeployService-EC2AccessCodeDeployRole-20241024T000000
 Select
Select EC2 on Use Case Tab。
1 | AmazonEC2FullAccess |
Add AmazonEC2, AmazonS3, and AWSCodeDeploy permissions.
2.2.2 AWSCodeDeployService-DepolyEC2Role-20241024T00000
 Select
Select CodeDeploy on Use Case Tab.
1 | AWSCodeDeployFullAccess |
Add AWSCodeDeploy permissions.
2.2.3 AWSCodeDeployService-GitAssumeRoleWithAction-20241024T000000
 Select
Select Access management -> Identity providers -> Add provider.
 Used to listen to
Used to listen to GitHub Actions.
Provider URL: token.actions.githubusercontent.com
Audience: sts.amazonaws.com
The GitHub Identity Provider then adds the AWSCodeDeployService-GitAssumeRoleWithAction-20241024T000000 role.

 Select
Select Assign Role -> Web identity -> GitHub organization.
1 | AmazonS3FullAccess |
Add S3, AWSCodeDeploy permissions.
2.3 Create Amazon EC2


- Fill in the name
ec2.cheaper.001 - Click
Amazon Linux 2023 AMI - Click
t3a.nano
Finally, click Launch instance to create EC2.
2.3.1 Associate Elastic IP address

- Click on
Elastic IPs - Click the
Allocate Elastic IP Addressbutton

- Select the name
ec2.paper.001where EC2 has just been created - Select the default
Private IP address - Click the
Associatebutton
2.3.2 Amazon Route 53

- Fill in the
sub-domain name - Fill in the EC2’s
Private IP address - Click the
savebutton
Successfully set up the static sub-domain name and IP address.
2.3.3 Add AWS IAM roles

- Select
Actions - Select
Security - Select
Modify IAM role
 Add
Add AWSCodeDeployService-EC2AccessCodeDeployRole-20241024T000000.
2.3.4 Install CodeDeploy Agent on Amazon EC2
Enter the Amazon EC2 terminal.

- Select
Connectbutton - Select
EC2 Instance Connecttab - Select
Connectbutton
 Successfully log into the
Successfully log into the Amazon EC2 terminal.
1 | sudo apt update |
Install CodeDeploy Agent
 Success,
Success, CodeDeploy Agent is running.
2.3.5 (Optional) Install Git on Amazon EC2
1 | sudo yum install git-all |
Install git and pull the project to Amazon EC2.
2.3.6 (Optional) Install NGINX
1 | sudo yum update |
Install NGINX
1 | sudo netstat -tunpl |
Show Amazon EC2 listening ports. At this moment NGINX is on port :80.
The default home page of NGINX is in /var/www/html/index.html.

 Ensure that
Ensure that Source and Destination are publicly accessible, set to 0.0.0.0/0.
2.3.7 Appspec.yml
Reference Articles:
- (AWS Dcos) CodeDeploy AppSpec file reference
- (AWS DevOps Blog) Build and Deploy Docker Images to AWS using EC2 Image Builder
- (AWS GitHub Example) Build and Deploy Docker Images to AWS using EC2 Image Builder
Appspec.yml is used to indicate the codeDeploy procedure code.
Deployment is divided into 5 steps: (1) BeforeInstall -> (2) BeforeInstall -> (3) AfterInstall -> (4) ApplicationStart -> (5) ValidateService.
In the root directory, add ./appspec.yml.
1 | version: 0.0 |
Sourceis the root directory of theGitHub project.Destinationis the project pulled intoAmazon EC2.
In addition, a new ./scripts folder, in which there are 5 xxxxxxxx.sh respectively.
1 | application-stop.sh |
There are 5 xxxxxxxx.sh in there, which are the 5 steps of codeDeploy.
(1) application-stop.sh
1 | #!/bin/bash |
Empty. There is no need to stop the application in this tutorial.
(2) before-install.sh
1 | #!/bin/bash |
Empty. There is no need to stop the application in this tutorial.
(3) after-install.sh
1 | #!/bin/bash |
Install NGINX
(4) application-start.sh
1 | #!/bin/bash |
restart NGINX
(5) validate-service.sh
1 | #!/bin/bash |
Empty. There is no need to stop the application in this tutorial.
2.3.8 Static Website Pages
Added ./icons folder, which shows the site image ic_alana_002_20241022_a.jpg.
Also, added index.html home page.
1 | <html lang="en" data-bs-theme="dark"> |
A simple static site with text and images.
If you have completed “2.3.5 Install GIT” and “2.3.6 Install NGINX”, you can type EC2 EIP or the domain name in your browser, to see the Static Website Pages.
2.4 Create AWS CodeDeploy
2.4.1 Create the AWS CodeDeploy application

- Fill in the application name
test.codeDeploy.001 - Select
EC2/On-premises - Select
Create applicationbutton
2.4.2 Create AWS CodeDeploy Deployment Group

- Select
Create deployment groupbutton

- Fill in the Deployment group name
test.deploymentGroup.001 - Select the IAM role,
AWSCodeDeployService-DepolyEC2Role-20241024T000000 - Remove
Enable load balancing, because this is the simplest DevOps pipeline case, so there is no need for additional AWS services
2.4.3 Create AWS CodeDeploy Deployment
 Go to
Go to test.deploymentGroup.001 Select
Select Create deployment button
 First, Select
First, Select My application is stored in GitHub
- Fill
GitHub token name - Fill in the Repository name,
codedeploy.nginx.001 - Fill in
Commit ID - Select
Create deploymentbutton
2.4.4 Successful run of AWS CodeDeploy
 Successfully run
Successfully run AWS codeDeploy
2.5 Create GitHub Actions
Reference Articles:
2.5.1 Create GitHub Actions workflow



- Click
New workflowbutton - Select
set up a workflow yourselflink - After writing the
GitHub Actionscommand, click theCommit changesbutton
2.5.2 Configurate GitHub Actions secrets and variables

- Select
Settings Tab - Select
Secrets and variables->ActionsTab - Select
Secrets Tab
2.5.3 Add GitHub Actions secrets variables

- Add a new secrets variable with name
IAMROLE_GITHUB_ARN - The value is the ARN of the IAM role
arn:aws:iam::{xxxxxxxxx}:role/AWSCodeDeployService-GitAssumeRoleWithAction-20241024T000000 - Click the
Add secretbutton
2.5.4 Add GitHub Actions variables

- Select
VariablesTab - Add four of
Actions Variables - Select
New repository variablebutton
| Variables Name | Value | Description |
|---|---|---|
| AWS_REGION | us-east-1 | The default region is US East (N. Virginia) |
| CODEDEPLOY_APPLICATION_NAME | test.codeDeploy.001 | 2.4.1 Create the AWS CodeDeploy application |
| CODEDEPLOY_DEPLOYMENT_GROUP_NAME | test.deploymentGroup.001 | 2.4.2 Create AWS CodeDeploy Deployment Group |
| IAMROLE_GITHUB_SESSION_NAME | AWSGitAssumeRoleWithAction | 2.2.3 AWSCodeDeployService-GitAssumeRoleWithAction-20241024T000000 |
2.5.5 Write GitHub Actions Code
.github/workflows/main.yml
1 | name: Deploy |
A basic version of the GitHub Actions Code.
2.5.6 Run GitHub Actions Code

- Select
ActionsTab - Select
DeployTab - Select
Run workflowbutton
2.5.7 Successfully running GitHub Actions


 Successfully ran
Successfully ran main.yml
4.0 Cost
| Plan | USD |
|---|---|
| Monthly cost | $11.83 |
| Total 12 months cost | $141.96 |
Overall, AWS’s prices are quite competitive. The most important thing is that CodeDeploy is cheap, and the cost of using Amazon EC2 t4g.nano is very low, so AWS is a low-cost + efficient cloud service provider.
4.1 Detailed Estimate
| Service | Monthly | First 12 months total (USD) |
|---|---|---|
| AWS CodeDeploy | $8.8 | $105.6 |
| Amazon EC2 | $1.533 | $18.4 |
| Amazon Route 53 | $0.4 | $4.8 |
| VPN Connection | $1.1 | $13.2 |

5.0 Summary
GitHub Actions + CodeDepoly are powerful DevOps tools that fulfill the principle of “think big, take small steps” in a business environment.
To conclude, let’s summarize the key points of this chapter:
5.1 Principles
- The new “Macro Portfolio” system is to comply with the “Least Effort Principle”, which includes (1) agile development, and (2) agile deployment
- The real issues were (1) the project took too long to deploy, and (2) automated deployment was not achieved
- Success is due to the following: (1) Other departments want small features in small increments. (2) More simplicity means more understanding of the problem’s root cause.
5.2 Action
- Give the “
Updated API Manual” to other departments to try before every Thursday - Simplicity is a good result of the Highest Standards because we performed (1) a “DIVE DEEP investigation” and (2) understanding the root cause of the problem
5.3 AWS DevOps
- The development engineer commits the code via
GitHub Push GitHub Actionstrigger workflowsIAMROLE_GITHUB_ARNauthorizes access to AWS resourcesGitHub ActionstriggersAWS CodeDeployAWS CodeDeploytriggers deployment toAmazon EC2instancesAWS CodeDeploypulls Github resources and deploys toAmazon EC2instances
5.4 AWS IAM (CodeDeploy, EC2, Github)
- AWSCodeDeployService-EC2AccessCodeDeployRole-20241024T000000
- AWSCodeDeployService-DepolyEC2Role-20241024T000000
- AWSCodeDeployService-GitAssumeRoleWithAction-20241024T000000
5.5 AWS CodeDeploy (Appspec.yml)
- BeforeInstall
- BeforeInstall
- AfterInstall
- ApplicationStart
- ValidateService
5.6 Cost
- Monthly cost: $11.83 (USD)
- Total 12 months cost: $141.96 (USD)
Postscript
 On 14 December 2024, I attended the annual Amazon Greater China Community Gathering. I am very thankful to AWS for bringing me an unforgettable experience.
On 14 December 2024, I attended the annual Amazon Greater China Community Gathering. I am very thankful to AWS for bringing me an unforgettable experience.
📷Shoot and 🎬Edit by Kenny Chan Also, thanks to Smile (Lingxi) Lv - Developer Experience Advocacy Program Manager for supporting AWS Community Builder.
Also, thanks to Smile (Lingxi) Lv - Developer Experience Advocacy Program Manager for supporting AWS Community Builder.







 I know that
I know that  Reference Articles:
Reference Articles:
 Deep Dive Lounge, Wing So.
Deep Dive Lounge, Wing So.