If I have a local server with an RTX3080 and 64GB of memory, do I still need AWS Sagemaker? The answer is: yes, there is still a need.
Although the hardware level of the local server is good, Sagemaker provides additional benefits that are particularly suitable for team development processes. These benefits include:
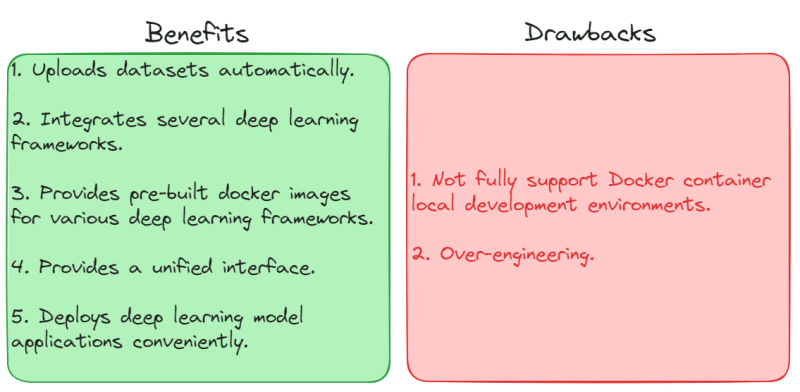
Sagemaker automatically uploads datasets (training set, validation set) to S3 buckets, with a timestamp suffix each time a model is trained. This makes it easy to manage data sources during a long-term development process.
Sagemaker integrates several popular deep learning frameworks, such as TensorFlow and XGBoost. This ensures code consistency.
Sagemaker provides pre-built docker images for various deep learning frameworks, including training images and server images, which accelerate local development time.
The inference.py in Sagemaker’s server image ensures a unified interface specification for models. Code consistency and simplicity are crucial in team development.
Sagemaker itself is a cloud service, making it convenient to deploy deep learning model applications.
However, Sagemaker has some drawbacks when it comes to training and deploying models locally. These drawbacks include:
Sagemaker does not fully support Docker container local development environments. In other words, using the jupyter/tensorflow-notebook image to develop Sagemaker sometimes generates minor issues. I will discuss this in more detail below.
Over-engineering. Honestly, although I am a supporter of Occam’s Razor and prefer solving practical problems with the simplest code, setting up Sagemaker on a local server can be somewhat over-engineered in terms of infrastructure.
In summary, for long-term team development, it is necessary to spend time setting up Sagemaker locally in the short term.
How to decide whether to set up Sagemaker on a local server?
I referred to the method in the AWS official documentation to quickly let you know whether Sagemaker should be set up on a local server or not.
https://docs.aws.amazon.com/sagemaker/latest/dg/docker-containers.html
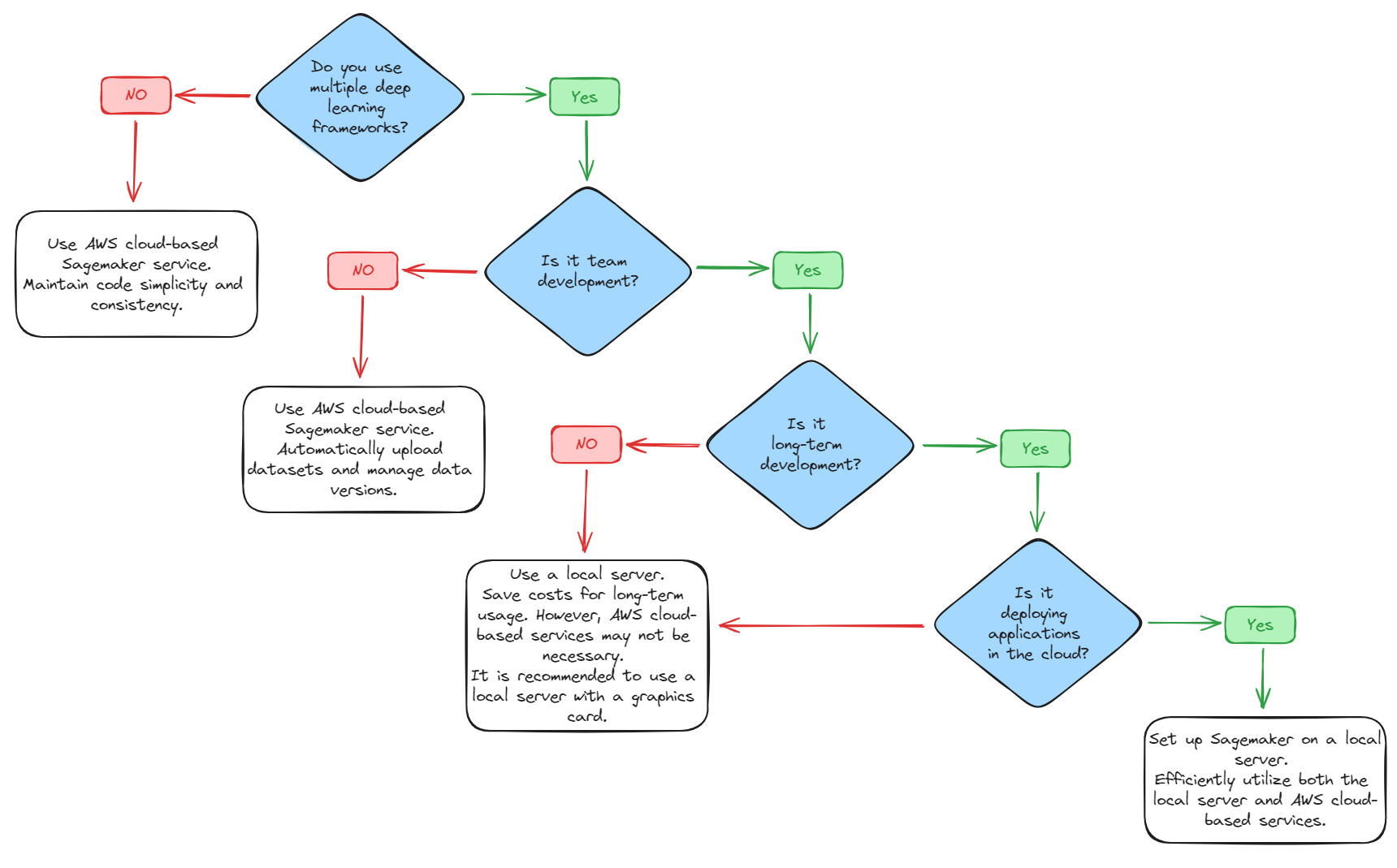
1. Do you use multiple deep learning frameworks?
No -> Use AWS cloud-based Sagemaker service. Maintain code simplicity and consistency.
Yes -> Go to question 2.
2. Is it team development?
No -> Use AWS cloud-based Sagemaker service. Automatically upload datasets and manage data versions.
Yes -> Go to question 3.
3. Is it long-term development?
No -> Use a local server. Save costs for long-term usage. However, AWS cloud-based services may not be necessary. It is recommended to use a local server with a graphics card.
Yes -> Go to question 4.
4. Is it deploying applications in the cloud?
No -> Use a local server.
Yes -> Set up Sagemaker on a local server. Efficiently utilize both the local server and AWS cloud-based services.
Local Server Architecture
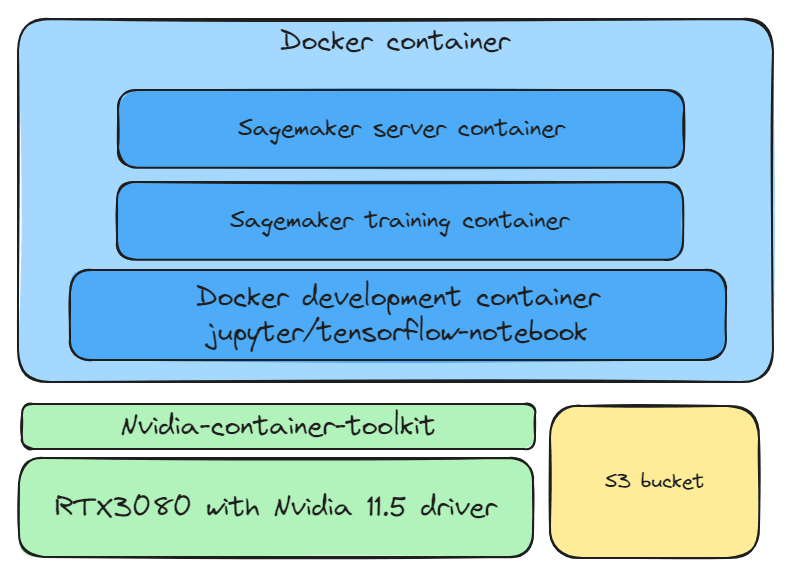
Nvidia 11.5 driver. RTX3080 is required for both training and deploying models.
Nvidia-container-toolkit, connecting Docker images with Nvidia 11.5 driver.
Docker development container environment, jupyter/tensorflow-notebook. Use Sagemaker to develop TensorFlow deep learning models.
Sagemaker training image. Sagemaker uses pre-built images to train models, automatically selecting suitable images for Nvidia, Python, and TensorFlow. Since I use TensorFlow, I use 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-training:2.11-gpu-py39.
Sagemaker server image. Sagemaker uses pre-built images to deploy models. This server image utilizes TensorFlow-serving (https://github.com/tensorflow/serving) and Sagemaker’s inference for model deployment. Since I use TensorFlow, I use 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-inference:2.11-gpu.
S3 bucket. Used to centrally manage datasets and model versions.
Useful Tips
Although these tips are very basic, in fast iteration cycles and team development, simple and practical tips can make development smoother and more efficient.
Clear naming
As the project develops over time, the number of dataset and model versions increases. Therefore, clear file naming conventions help maintain development efficiency.
1. Prefix
{Project Name}-{Model Type}-{Solution}
Whether it’s a dataset, model, or any temporary .csv file, it is best to have clear names to avoid forgetting the source and purpose of those files. Here are some examples of naming conventions I use.
{futurePredict}-{lstm}-{t5}
{futurePredict}-{train}-{hloc}
{futurePredict}-{valid}-{hloc}
2. Suffix
{Version Number}-{Timestamp}
After each model training, there are often new ideas. For example, when optimizing a LSTM model used for stock trading strategies by adding new momentum indicators, I would add this optimization approach to the suffix.
{volSignal}-{20240106_130400}
If there are no specific updates, generally, I use numbers to represent the current version.
{a.1}-{20240106_130400}
3. Clear project structure
./data/input
Datasets inputted into the model.
./data/output
Model outputs.
./data/tmp
All temporary files. In fast iteration cycles, it is common to lose temporary files, leading to a loss of data source traceability. Therefore, temporary files also need to be well managed.
./model
Location for storing models. Generally, Sagemaker automatically manages datasets and models, but it is still recommended to store them locally for convenient team development.
./src
Supporting libraries, such as Sagemaker’s inference.py, and common toolkits for model training.
Practical Experience: Why Sagemaker Does Not Fully Support Local Docker Container Development
The support of Sagemaker for local development is not very favorable. Below are two local development issues that I have encountered. Although I have found similar issues raised on Github, there is still no satisfactory solution available at present.
1. Issue with local container Tensorflow-Jupyter development environment
When training models, Sagemaker displays an error regarding the docker container (No /opt/ml/input/config/resourceconfig.json).
The main reason is that after executing estimator.fit(...), Sagemaker’s Training image reads temporary files in the /tmp path. However, Sagemaker does not consider the local container Tensorflow-Jupyter. As a result, these temporary files in /tmp are only available in the local container Tensorflow-Jupyter, causing errors when the Training image of Sagemaker tries to read them.
Here is the solution I provided:
https://github.com/aws/sagemaker-pytorch-training-toolkit/issues/106#issuecomment-1862233669
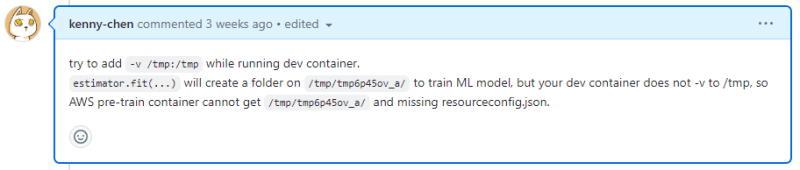
Solution: When launching the local container Tensorflow-Jupyter, add the "-v /tmp:/tmp" command to link the local container’s /tmp with the local /tmp, which solves this problem.
Here is the code I used to launch the local container:sudo docker run --privileged --name jupyter.sagemaker.001 --gpus all -e GRANT_SUDO=yes --user root --network host -it -v /home/jovyan/work:/home/jovyan/work -v /sagemaker:/sagemaker -v /var/run/docker.sock:/var/run/docker.sock -v /tmp:/tmp -v /sagemaker:/sagemaker sagemaker/local:0.2 >> /home/jovyan/work/log/sagemaker_local_date +\%Y\%m\%d_\%H\%M\%S.log 2
2. Issue with Sagemaker’s local server image
Sagemaker’s local server image defaults to using the inference method for deployment, so there is no inference.py in the server image. Therefore, model.fit(...) followed by model.deploy(...) results in errors.
The error messages are not clear either. Sometimes, it displays "/ping" error, and other times, "No such file or directory: 'inference.py'" error.
Here is the solution I provided:
https://github.com/aws/sagemaker-python-sdk/issues/4007#issuecomment-1878176052
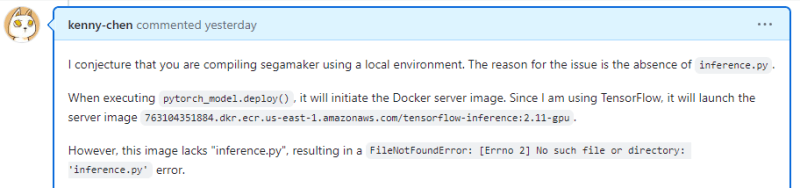
Solution: Save the model after model.deploy(...). Then, use sagemaker.tensorflow.TensorFlowModel(...) to reload the model and reference ./src/inference.py.
Although the inference method is a more convoluted way to locally deploy models, it is useful for adding middleware business logic on the server side and is a very valuable local deployment approach.
Summary
I know that Sagemaker’s cloud service offers many amazing services, such as preprocessing data, batch training, Sagemaker-TensorBoard, and more. For developers who need to quickly prototype, these magical services are perfect for them.
Although setting up Sagemaker architecture on a local server may be more complex, Sagemaker provides standardized structure, automated processes, integrated unified interfaces, and pre-built resources. In the long run, I recommend setting up Sagemaker on a local server.