Introduction
In my previous articles, I used two different trading strategies to explain the best practices of batch-transform and real-time endpoints, as well as the reasons for using EC2. These articles can be referred to as “Even though Sagemaker provides various benefits, why do I still use EC2?“ and “Why Choose Sagemaker Despite Having a Local Server with RTX3080?“.
In this article, I will first demonstrate the complete architecture of SageMaker.
Then, I will explain the reasons for using Multi-Modal-Single-Container + Microservices and not using Application Load Balancer.
Finally, I will use two different trading strategies to explain the best practices of data parallelism and model parallelism in advanced training models.
Architecture Overview
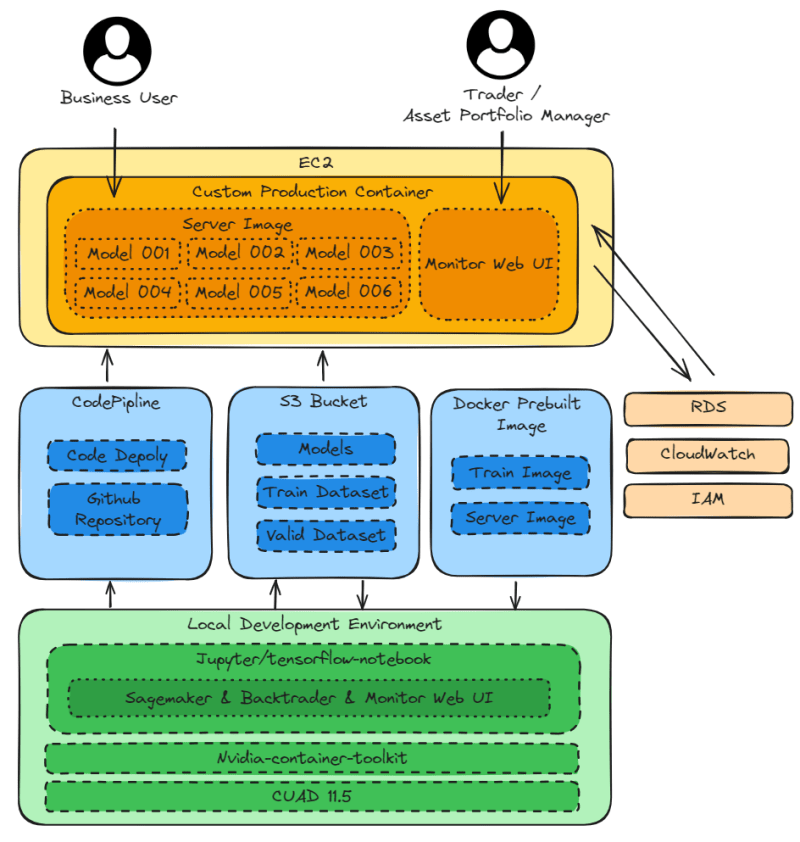
Local Development Environment
CUDA 11.5andNvidia-container-toolkitfor local model training.jupyter/tensorflow-notebookfor local development environment, with libraries required forSagemaker[local],Backtrader, andMonitor Web UIinstalled in the image.
Supported AWS services
Sagemaker prebuilt imagesfor pulling images to thelocal development environmentfor local model training and testing.S3 Bucketfor storing datasets and models.CodePiplinefor deploying projects onGithubtoEC2production environment.
EC2
Custom Production Containerwith libraries required for Sagemaker, Backtrader, and Monitor Web UI.Monitor Web UIfor presenting the trading performance of the model in graphical form, providing:80to Trader and Asset Portfolio Manager.Server Imagefor deploying models using Sagemaker prebuilt image, providing:8080to business user.
Managed AWS Services
RDSfor storing model results. Monitor Web UI in EC2 retrieves the data from RDS and presents the trading performance in graphical form.CloudWatchfor monitoring the computation and storage of EC2, RDS, and S3 Bucket.IAMfor helping jupyter/tensorflow-notebook in local development environment to access Sagemaker prebuilt images and S3 Bucket.
Why not use Application Load Balancer and instead create Multi-Modal-Single-Container + Microservices on EC2 to handle errors?
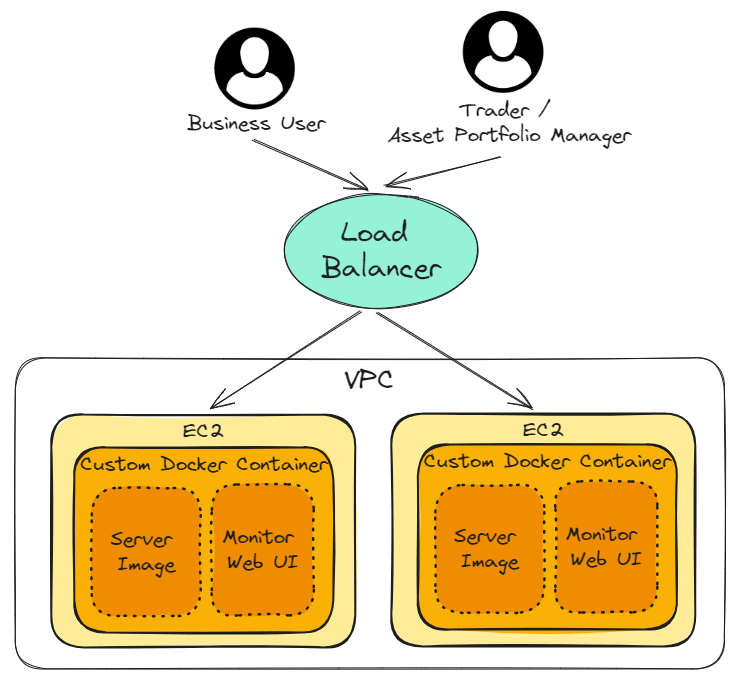
Application Load Balancer is a remarkable service. In fact, it can also be used to handle errors. However, in the case of trading strategies, I would choose to handle errors with Multi-Modal-Single-Container + Microservices.
Here are my three error handling methods:
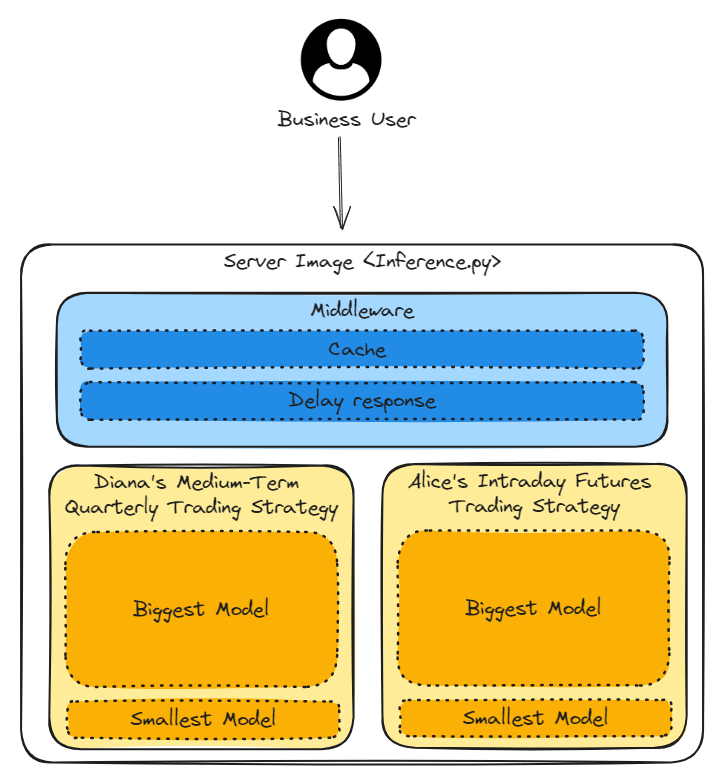
The goal of the following three error handling methods is to flexibly reduce hardware resource requirements.
1.Switch to Smallest Model
There are two trading strategies (Diana’s medium-term quarterly trading strategy and Alice’s intraday futures trading strategy). Each trading strategy has two versions of the model, where the Biggest Model provides high accuracy but requires high hardware resources. On the contrary, the Smallest Model provides low accuracy but requires low hardware resources.
If the server is in a high computational state, switching to the Smallest Model can reduce the hardware resource requirements and keep the application running smoothly.
2. Response caching results
When the same business user uses the application frequently, returning cached data can avoid overloading hardware resources.
3. Delayed Response time
When hardware resources are overloaded, delaying the response time can release the hardware resources.
Advantages of Multi-Modal-Single-Container + Microservices
Here are my examples of trading strategies to explain the reasons for using Multi-Modal-Single-Container + Microservices.
1.Trading strategies have high fault tolerance
Both trading strategies anticipate reduced profits due to slippage during trading. This design with high fault tolerance can accommodate various hardware issues, such as switching to the Smallest Model, response caching results, and delayed response time.
Additionally, it can handle errors from market makers, such as delayed quotes, partial executions, and wide bid-ask spreads.
2. Shared hardware resources
The frequency and time of use of two trading strategies are different, allowing for full utilization of idle hardware resources.
3. Deployment of trading strategies in different regions
Diana’s medium-term quarterly trading strategy targets global assets. By deploying trading strategies independently in Hong Kong and the United States, the latency can be reduced.
Furthermore, if the hardware in Hong Kong completely stops working, the hardware in the United States can be used to hedge the risk by purchasing short options of overseas ETF.
Best Practices of Data Parallelism and Model Parallelism in Advanced Training Models
Sagemaker provides remarkable advanced training methods: Data parallelism and Model parallelism. I will use two different trading strategies to explain the best practices of data parallelism and model parallelism in advanced training models.
Data parallelism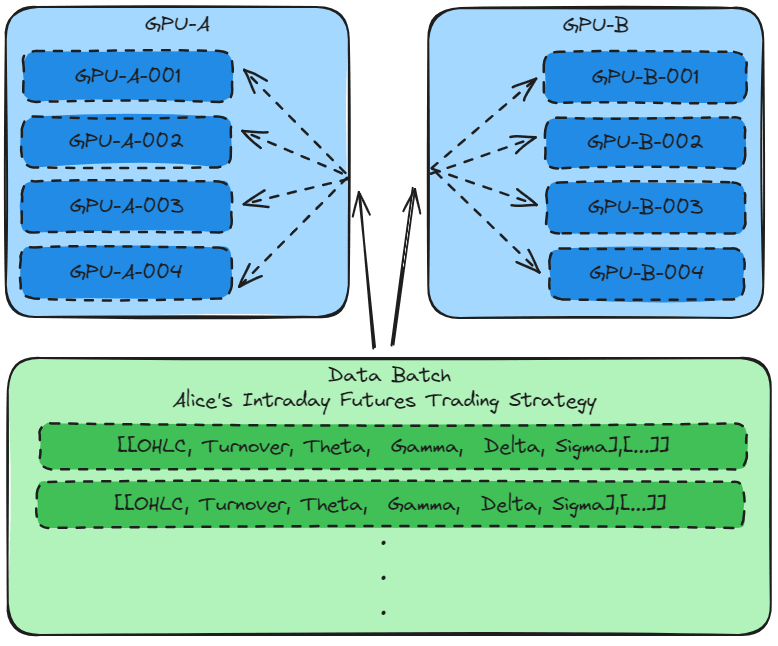
Model parallelism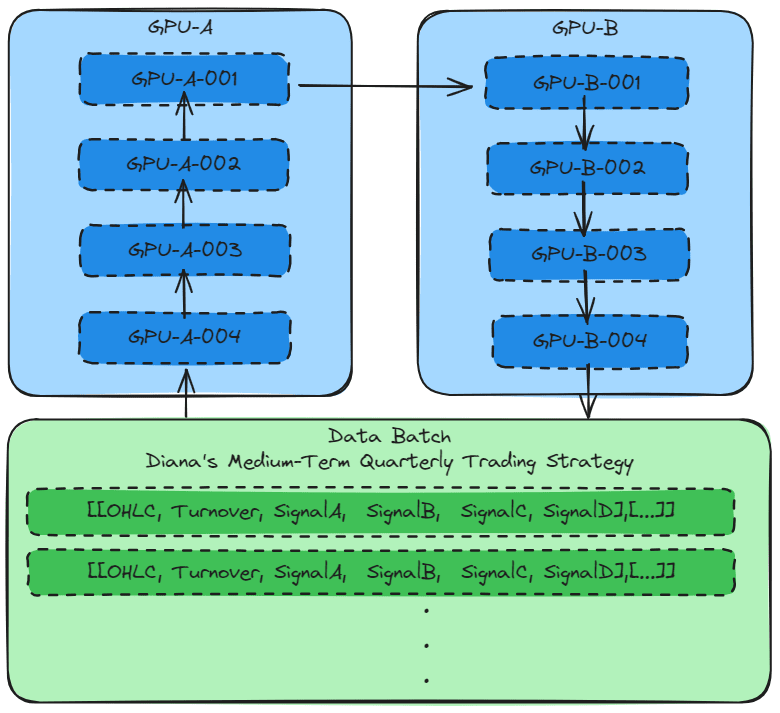
Model Parallelism: A simple method of model parallelism is to explicitly assign layers of the model onto different devices.Data Parallelism: Each individual training process has a copy of the global model but trains it on a unique slice of data in parallel with others.
– Accelerate Deep Learning Workloads with Amazon SageMaker, chapter10
In simple terms, if the data can be divided into small groups, Data parallelism is used. If the model can be divided into small groups, Model parallelism is used.
Alice’s intraday futures trading strategy
The intraday trading strategy mainly uses a few key indicators to train the model, providing entry and exit points. Therefore, the data samples are large.
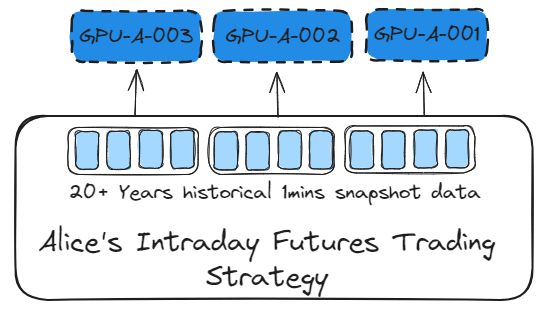
When the data sample is large and the model has only a few algorithms, Data parallelism should be used to train the model. This allows the data set to be split and computed on different GPUs.
1 | distribution = { |
3_SDP_finetuning_pytorch_models.ipynb
Sagemaker provides remarkable advanced training methods. By setting the distribution parameter, Data parallelism can be used to train the model.
Diana’s Medium-Term Quarterly Trading Strategy
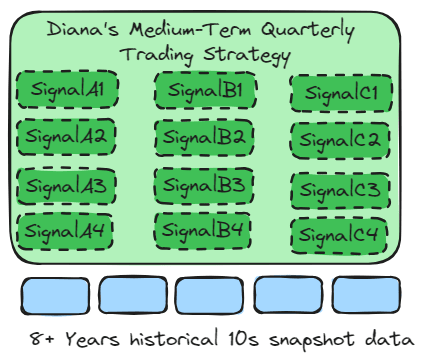
The macro trading strategy mainly uses dozens of key indicators to provide overseas asset allocation forecasts. The minimum data set is 8 years (2 bull and bear cycles) of hourly snapshot data.
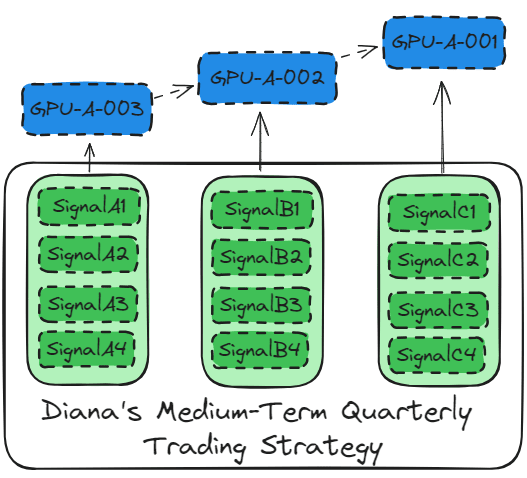
When the main algorithms can be split into small groups, Model parallelism is used to train the model. This allows the model tensor to be computed in batches on different GPUs.
1 | distribution={ |
3_SDP_finetuning_pytorch_models.ipynb
Similarly, by setting the distribution parameter, Model parallelism can be used to train the model.
Conclusion
AWS provides convenient solutions for the financial industry. Sagemaker seamlessly integrates deep learning workflow into production environments. Additionally, Sagemaker offers surprising features to accelerate development. I will continue to learn about new AWS products and share examples of AWS services in finance and trading.