Introduction
I am extremely delighted to have participated in the AWS re:Invent re:Cap event held in Hong Kong, which provided me with exposure to the latest AI solutions offered by AWS.
In my previous article, although I discussed deploying deep learning models in production using EC2, such a solution is only suitable for my personal use case, which can be found in the article “Machine Learning Trading Strategy Best Practices for AWS SageMaker“.
In this article, I will first discuss the advantages of deploying models in production using SageMaker after training them locally. I would like to express my gratitude to Raymond Tsang for providing valuable insights.
Next, I will delve into the benefits of training models using SageMaker as opposed to local training. I would like to thank Yanwei CUI for sharing their insights.
Lastly, I will explain a more efficient trading strategy architecture, with special thanks to Wing So for their valuable input.
1. The Benefits of Deploying Models in Production with SageMaker
The greatest advantage of SageMaker lies in its data security, auto scaling, and container deployment capabilities. If high data security, handling sudden traffic spikes, and agile development processes are required, leveraging these advantages of SageMaker can significantly accelerate development and deployment timelines.
However, after training models locally, can one deploy them in production using SageMaker? In other words, is it possible to utilize only specific functionalities of SageMaker?
Answer: Yes, it is possible to use only certain functionalities of SageMaker.
In the case of my use case, “Alice’s Intraday Futures Trading Strategy,” which is a daily trading strategy model with fixed trading times and a predictable number of requests, the model is susceptible to market sentiment and unexpected news events, necessitating monthly model updates.
In such a scenario, deploying the model in a production environment using SageMaker offers the following advantages:
- SageMaker allows for
container deployment, making it easier to manage custom inference code within the deployment image. - SageMaker’s endpoint supports
version iterations, facilitating agile development processes. - SageMaker supports
multi-modeldeployment in asingle endpoint, enabling easier management of multiple model interfaces.
While local model training is preferred in my use case, there are still advantages to using SageMaker for model training.
2. The Advantages of Training Models with SageMaker
If there are two RTX3080 graphics cards available on the local server, is there still a need to use AWS SageMaker for training models? In other words, can one replace the pay-as-you-go model training of SageMaker with a one-time higher fixed cost?
Answer: Yes, it is possible. However, if one wishes to avoid the time-consuming process of hardware deployment or simply desires to utilize higher-end hardware for a shorter duration, training models using SageMaker is more suitable.
Furthermore, SageMaker optimizes data-batch processing and floating-point operations to accelerate model training speed.
In the case of my use case, “Diana’s Medium-Term Quarterly Trading Strategy,” which involves multi-asset trading in four major markets (US stocks, Hong Kong stocks, US bonds, and USD currency), the optimized data-batch processing of SageMaker can be utilized for the four main markets.
Additionally, the optimized floating-point operations of SageMaker can be applied to the three core technical indicators within the model (high dividend stocks, low volatility, and capital accumulation).
Therefore, gaming graphics cards have limitations when it comes to model training.
3. A More Efficient Trading Strategy Architecture
Whether using EC2 or SageMaker container deployment, both options serve to expedite development time. However, considering the overall efficiency of the trading system, two factors need to be considered: streaming data processing and the layer at which computations are performed.
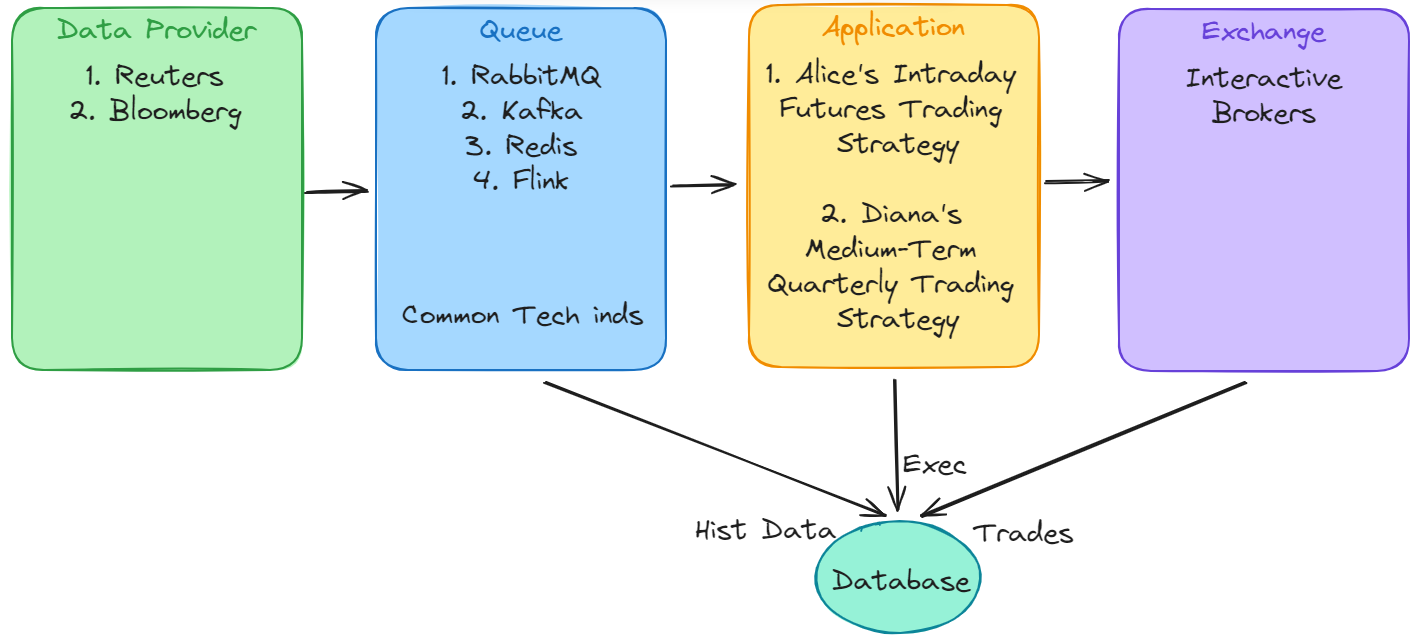
The key to achieving higher efficiency lies in the Queue layer.
After the Data Provider delivers streaming data, the Queue distributes the data to the Application while simultaneously storing the streaming data in a database. This reduces latency and improves overall efficiency.
Furthermore, performing computations at the Queue layer for the technical indicators used by all Applications prevents redundant calculations and enhances overall efficiency.
However, further investigation is required to determine which Queue framework to use.
Summary
The theme of AWS re:Invent re:Cap, “Gen AI,” was a captivating event. There were many intriguing segments, such as the “Deep Dive Lounge,” “Lighting Talk,” and “Game Jam,” which provided delightful surprises.
 Deep Dive Lounge, Wing So.
Deep Dive Lounge, Wing So.
More importantly, numerous AWS solution architects have contributed to the advancement of my trading endeavors, offering lower-cost solutions and improved computational efficiency. Lastly, I would like to express my special thanks to Raymond Tsang, Yanwei CUI, and Wing So for their invaluable assistance.